Recap: Wie sind wir hier gelandet? Es ist Quasi-Konsens, dass LLMs keine Buchstaben zählen können und auch sonst Probleme haben “Buchstaben” zu verstehen. In Teil 1 bin ich darüber gestolpert, dass sie das plötzlich beides fast perfekt können.
WO IST DAS LIMIT?
Buchstaben zählen in Wörtern und kurzen Texten klappt also super … irgendwann fängt der Gedanke in mir an zu nagen … wo ist denn die Grenze und was können die Modelle noch?! Damit habe ich dann die letzten Wochen verbracht und ordentlich Geld / Credits für OpenRouter (alle Modelle über einen Anbieter / API verfügbar), Claude Code und HuggingFace Inference Endpoints (OpenSource Modelle einfach / flexibel hosten) investiert. Und … meine gute alte Workstation mit 2 Nvidia RTX 3090 habe ich auch wieder dafür in Betrieb genommen :D. Die Frage hat mich echt nicht losgelassen.
Also … gehen wir dem Ganzen auf den Grund: Wo ist die Grenze des “Buchstabenverstehens”?
DER EXPERIMENTIERKASTEN
Erst ein bisschen wild und planlos und ohne eine wirkliche Grenze zu entdecken - dann ein bisschen strukturierter - habe ich einen kleinen Benchmark aufgebaut.
DIE MODELLE
Die besten Modelle des StrawberryBench - Gemini 3.1 Pro, Qwen 3.5 397B und Grok 4. Opus 4.6 wäre noch spannend gewesen - war aber leider über OpenRouter super unzuverlässig und langsam.
DER KORPUS
Um den Schwierigkeitsgrad deutlich zu erhöhen habe ich aktuelle Nachrichten in 11 Sprachen (Deutsch, Englisch, Spanisch, Französisch, Italienisch, Niederländisch, Polnisch, Portugiesisch, Rumänisch, Schwedisch und Türkisch) gecrawled und damit einen Testdatensatz erstellt.
Quellen waren z.B. spiegel.de, bbc.com, lemonde.fr, elmundo.es, repubblica.it, nrc.nl, …
DREI EXPERIMENTE
Buchstaben zählen: Der Klassiker - “Wie oft kommt der Buchstabe e in diesen 5 Artikeln vor?”
Wörter finden: “Finde alle Wörter, in denen ein o vor einem m vorkommt.” - Hier muss das Modell nicht nur einzelne Buchstaben erkennen, sondern ihre Reihenfolge innerhalb von Wörtern verstehen.
Substring finden: “An welcher Zeichenposition beginnt dieser Textausschnitt?” - Das Modell muss eine exakte Position eines 20 - 50 Zeichen langen Substrings in einem langen Text finden.
UND AB DIE POST
Damit haben wir 11 Sprachen x 3 Textlängen x 3 Modelle x 3 Experimente = 495 aufwändige LLM Calls … das hat eine Weile gedauert. Pro Call teilweise bis zu 10 Minuten weil die Modelle SEEEHHHHRRR genau nachgedacht haben (mehr weiter unten).
AUFGABE 1: BUCHSTABEN ZÄHLEN
So, noch mal zum mitschreiben, es geht darum zu zählen, wie oft ein Buchstabe in Nachrichtentexten mit 1.000 (halbe A4 Seite), 5.000 (~2,5 A4 Seiten) und 10.000 (~5 A4 Seiten) vorkommt. Aus dem Bauch - und bei allem was man glaubt zu wissen - eine unlösbare Aufgabe.
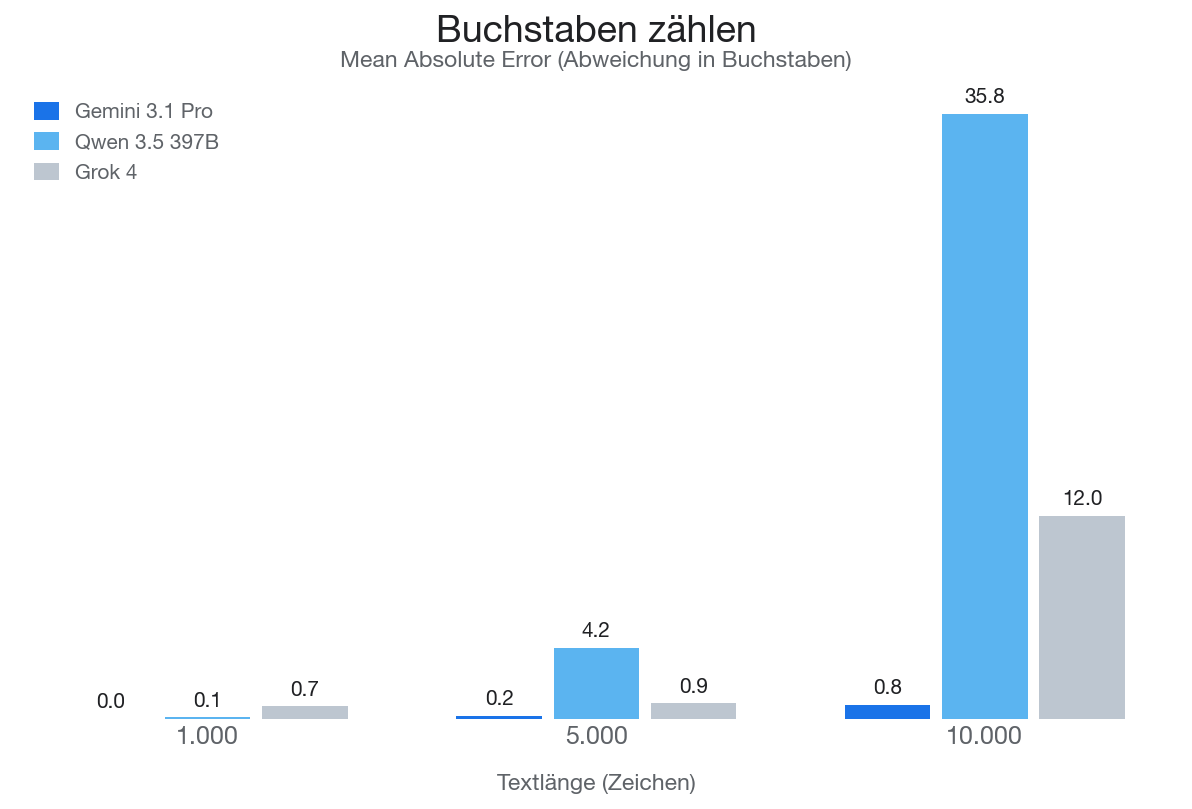
Genau hinschauen - besonders bei Gemini! Bei 1.000 Zeichen liegen alle Modelle im Schnitt weniger als 1 Buchstabe daneben. Bei 10.000 Zeichen? Qwen liegt im Schnitt fast 36 Buchstaben daneben. Gemini bleibt selbst da bei unter einem. Das ist … bemerkenswert.
Die Tabelle veranschaulicht das noch einmal. Kommt der zu suchende Buchstabe z.B. 5 mal vor, liegt die durchschnittliche Abweichung (Mean Absolute Error) bei <1. Kommt der zu suchende Buchstabe >151 mal im Text vor, liegt Gemini im Schnitt nur 1,2 gezählte Buchstaben daneben. Unreal!
| Bucket (wie oft kommt der Buchstabe tatsächlich im Text vor) |
n | gemini-3.1-pro-preview | qwen3.5-397b-a17b | grok-4 | Total |
| 1–10 | 18 | 0.0 (0%) | 0.8 (14%) | 0.3 (8%) | 0.4 (8%) |
| 11–30 | 27 | 0.0 (0%) | 0.4 (2%) | 0.8 (4%) | 0.4 (2%) |
| 31–60 | 21 | 0.0 (0%) | 3.0 (6%) | 1.0 (2%) | 1.3 (3%) |
| 61–150 | 6 | 0.0 (0%) | 39.0 (39%) | 2.0 (2%) | 13.7 (13%) |
| 151+ | 27 | 1.2 (0%) | 37.1 (14%) | 14.4 (5%) | 16.8 (6%) |
| Total | 99 | 0.3 (0%) | 12.7 (10%) | 4.5 (4%) | 5.8 (5%) |
79% der falschen Antworten sind Undercounting — die Modelle übersehen Buchstaben, statt welche dazuzuerfinden. Bei langen Texten gehen Details verloren.
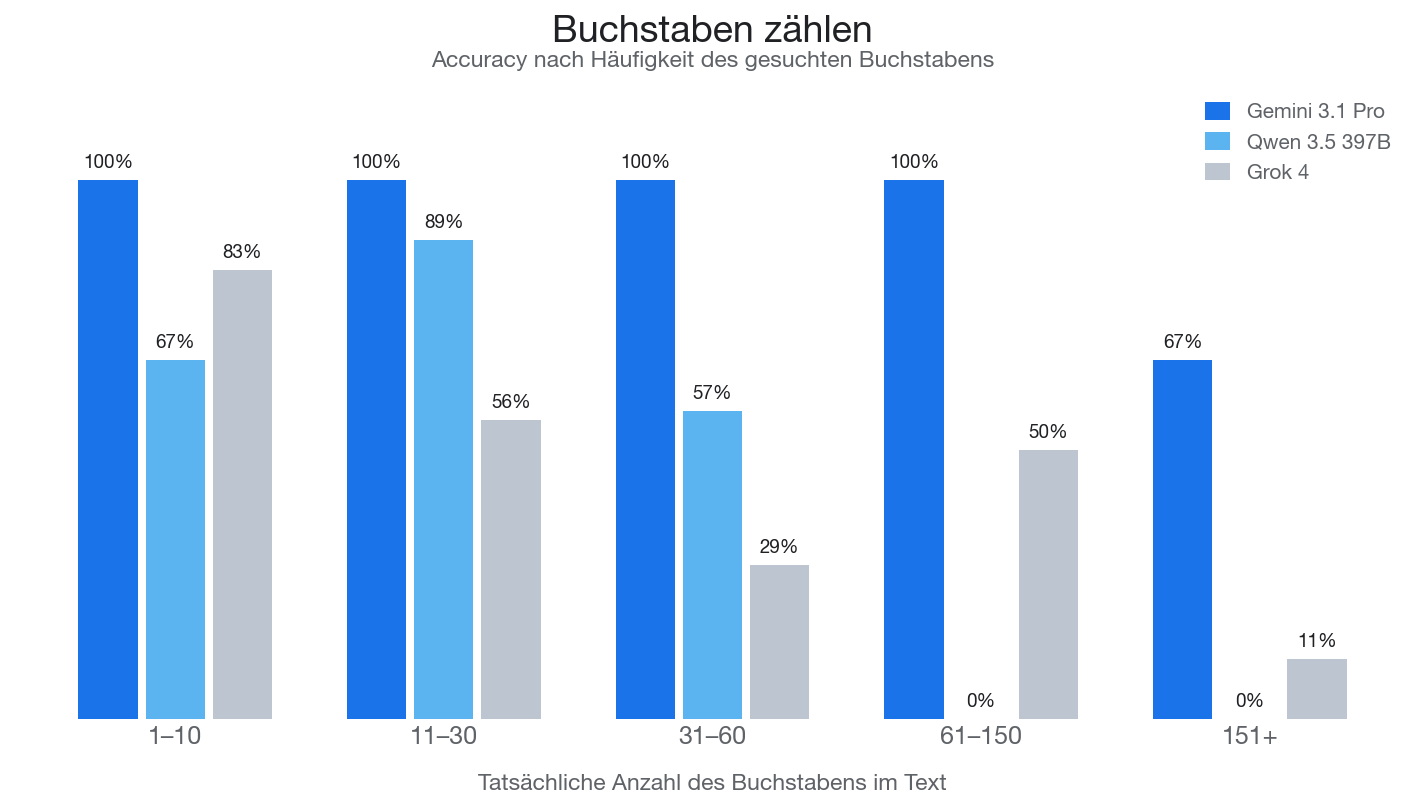
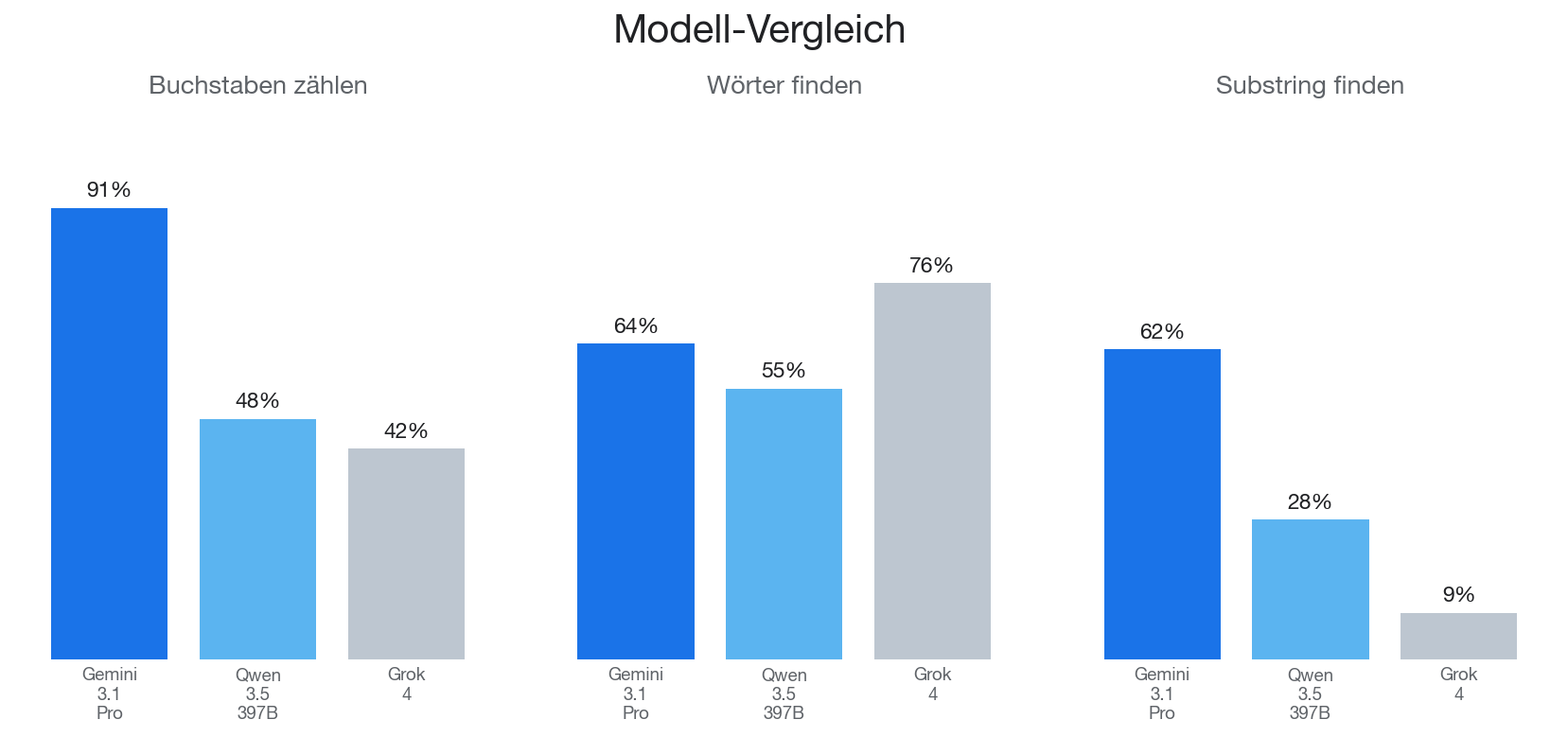
Hier noch eine Auswertung zur Genauigkeit nach Buchstabenhäufigkeit - also wie oft die Modelle tatsächlich genau das richtige Ergebnis zurückgegeben haben. Gemini dominiert mit 91% Gesamtaccuracy. Qwen liegt bei 48%, Grok bei 42%.
AUFGABE 2: WÖRTER FINDEN
Immer noch kein Limit gefunden. Also machen wir es den Modellen schwerer. “Finde alle Wörter, in denen ein o vor einem m vorkommt”. Die Modelle müssen also zwei Buchstaben in einem Wort und deren Reihenfolge erkennen. Im zweiten Schritt müssen sie die eindeutigen Wörter identifizieren. Was Ähnliches wurde hier untersucht (Spoiler: hat nicht gut funktioniert). Und BOOM:
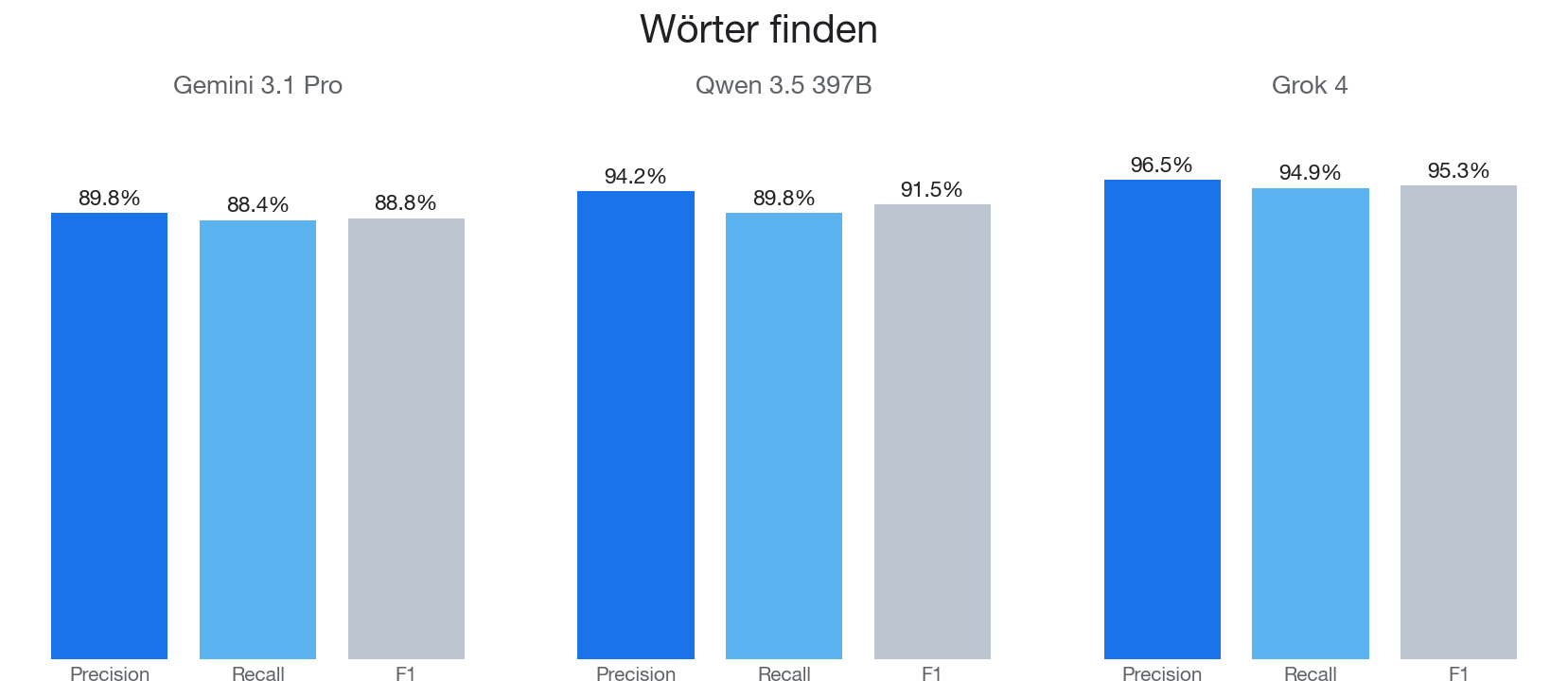
Precision - Wurden auch nur Worte erkannt, die wirklich beide Buchstaben in der richtigen Reihenfolge enthalten?
Recall - Wurden alle Worte erkannt, die beide Buchstaben in der richtigen Reihenfolge enthalten?
F1 - harmonisches Mittel aus Precision / Recall
Die Precision ist durchgehend etwas höher als der Recall. Das bedeutet: Modelle vergessen eher Wörter, als dass sie welche halluzinieren. Was sie antworten, stimmt meistens - sie übersehen nur ab und zu eins. Und die Werte sind wirklich überraschend gut. Meist wird maximal ein Wort übersehen oder “dazugedichtet”.
Grok dominiert mit 95.3% F1, 96.5% Precision und 94.9% Recall — das ist nah an perfekt. Gemini landet hier mit 88.8% F1 am Ende.
Hier noch mal die Ergebnisse im Detail nach Textlänge und Accuracy (also hat das Modell exakt die richtigen Wörter erkannt).
| Model | 1,000 | 5,000 | 10,000 | Total |
| gemini-3.1-pro-preview | 8/11 (73%) | 7/11 (64%) | 6/11 (55%) | 21/33 (64%) |
| qwen3.5-397b-a17b | 7/11 (64%) | 7/11 (64%) | 4/11 (36%) | 18/33 (55%) |
| grok-4 | 10/11 (91%) | 9/11 (82%) | 6/11 (55%) | 25/33 (76%) |
| Total | 25/33 (76%) | 23/33 (70%) | 16/33 (48%) | 64/99 (65%) |
Aber hier lohnt es sich, die Fehler genauer anzuschauen. Denn 44% der verpassten Wörter enthalten Apostrophe, Bindestriche oder typographische Anführungszeichen: d'extrême, l'enquête, government-funded, mountbatten-windsor, dell'hockey, jacques-elie. Statt d'extrême wird z. B. extrême erkannt oder statt mountbatten-windsor nur windsor.
Über die Hälfte aller fehlerhaften Antworten (54%) sind von diesem Problem betroffen. Wenn man sie rausrechnet, wären die tatsächlichen Ergebnisse also nochmal besser als die Charts zeigen. Eine Verbesserung des Prompts oder des Codes könnte hier einige “Fehler” eliminieren, die eigentlich gar keine sind.
Besonders schwierig bleiben aber echte Sonderzeichen: Die schlimmsten Fehler passieren bei Buchstabenpaaren wie e→ę (Polnisch), ê→m (Französisch) oder ğ→a (Türkisch).
AUFGABE 3: SUBSTRING FINDEN
“An welcher Zeichenposition beginnt dieser Textausschnitt?” - Sollte auch maximal schwierig für LLMs sein … und wir werden wieder verblüfft! 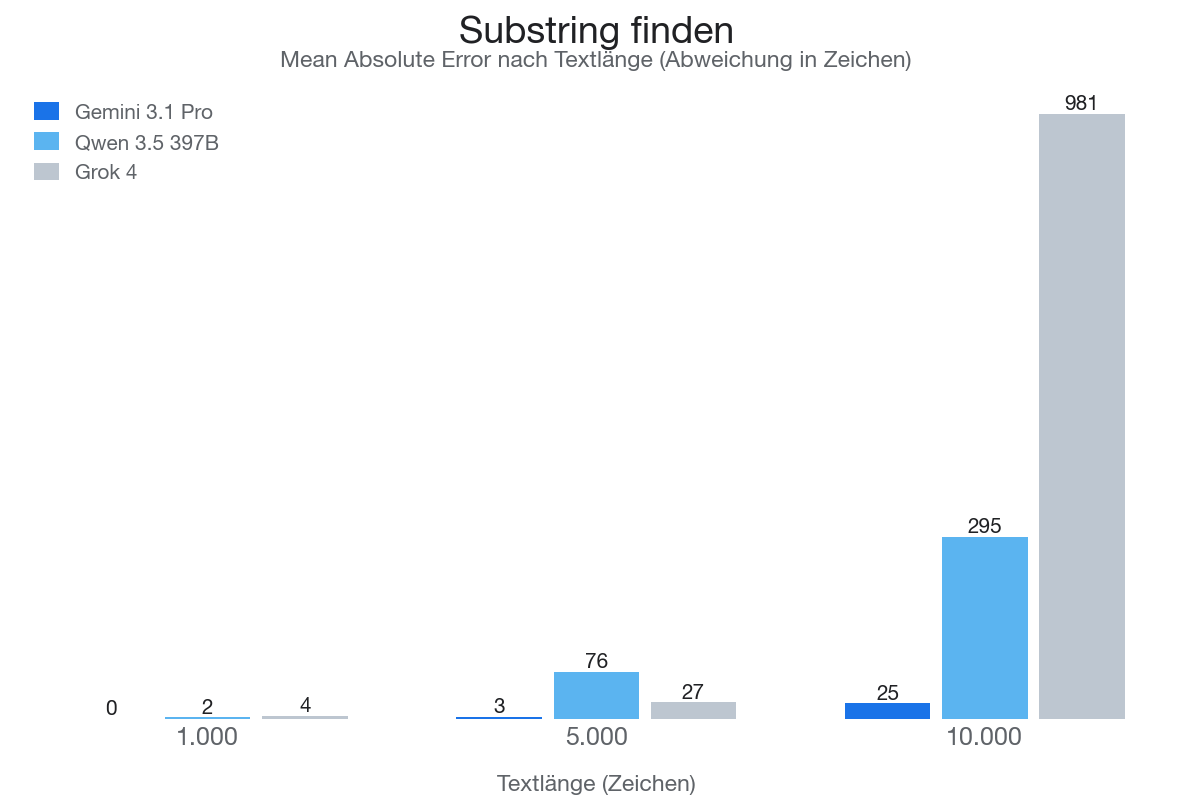
Schaut noch mal auf Gemini! Kurze, mittlere, lange Texte … alles fast Perfekt gelöst. Unerklärlich!
Insgesamt liegen alle Modelle bei 1.000 Zeichen nur wenige Zeichen daneben. Bei 10.000 Zeichen explodieren die Fehler dann aber teilweise: Grok liegt im Schnitt 981 Zeichen daneben, Qwen 295. Gemini bleibt auch da mit 25 Zeichen vergleichsweise harmlos.
MODELLVERGLEICH
WIE VIEL “DENKEN” DIE MODELLE?
Alle drei Modelle sind “Reasoning”-Modelle: Sie “denken” erstmal eine Weile nach, bevor sie tatsächlich antworten - aber wie viel “denken” sie denn tatsächlich?
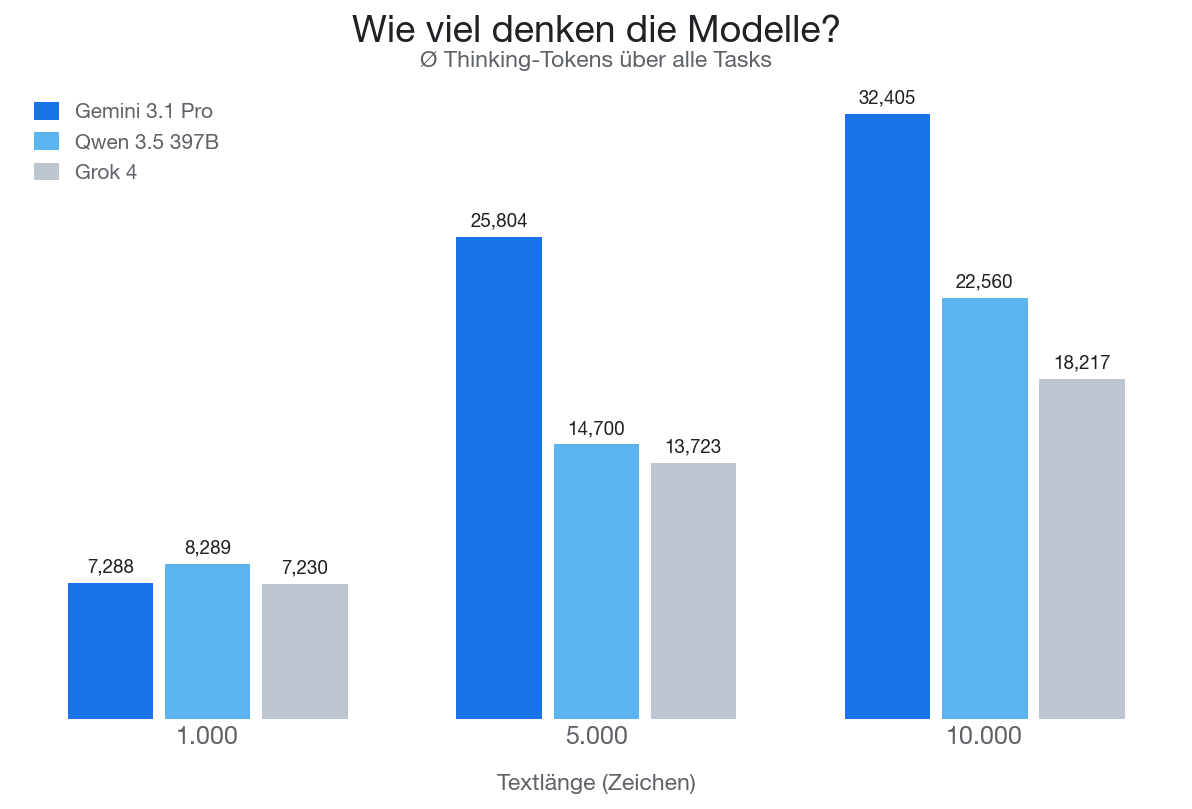
Gemini denkt am meisten - bei 10.000-Zeichen-Texten im Schnitt über 32.000 Tokens. Grok denkt am wenigsten, nur gut die Hälfte davon. Das korreliert grob mit der Performance beim Buchstabenzählen und Substring-Finden: Mehr Nachdenken = bessere Ergebnisse.
Ausnahme: Grok denkt wenig und ist trotzdem der Beste beim Wörterfinden.
Dazu kommen wir im nächsten Teil noch im Detail - aber dieses Rumgedenke ist für mich ein Indiz, dass wirklich das Modell die Aufgabe löst, und nicht “Magie” in der Modell-Blackbox am Werk ist.
UND JETZT MOMENT NOCH MAL …
… NICHTS davon, was wir uns eben zusammen angeschaut haben, dürfte eigentlich funktionieren?!?!?! Jahrelang hat man dieses Phänomen rauf und runter diskutiert - damit Likes und Kommentare gesammelt.
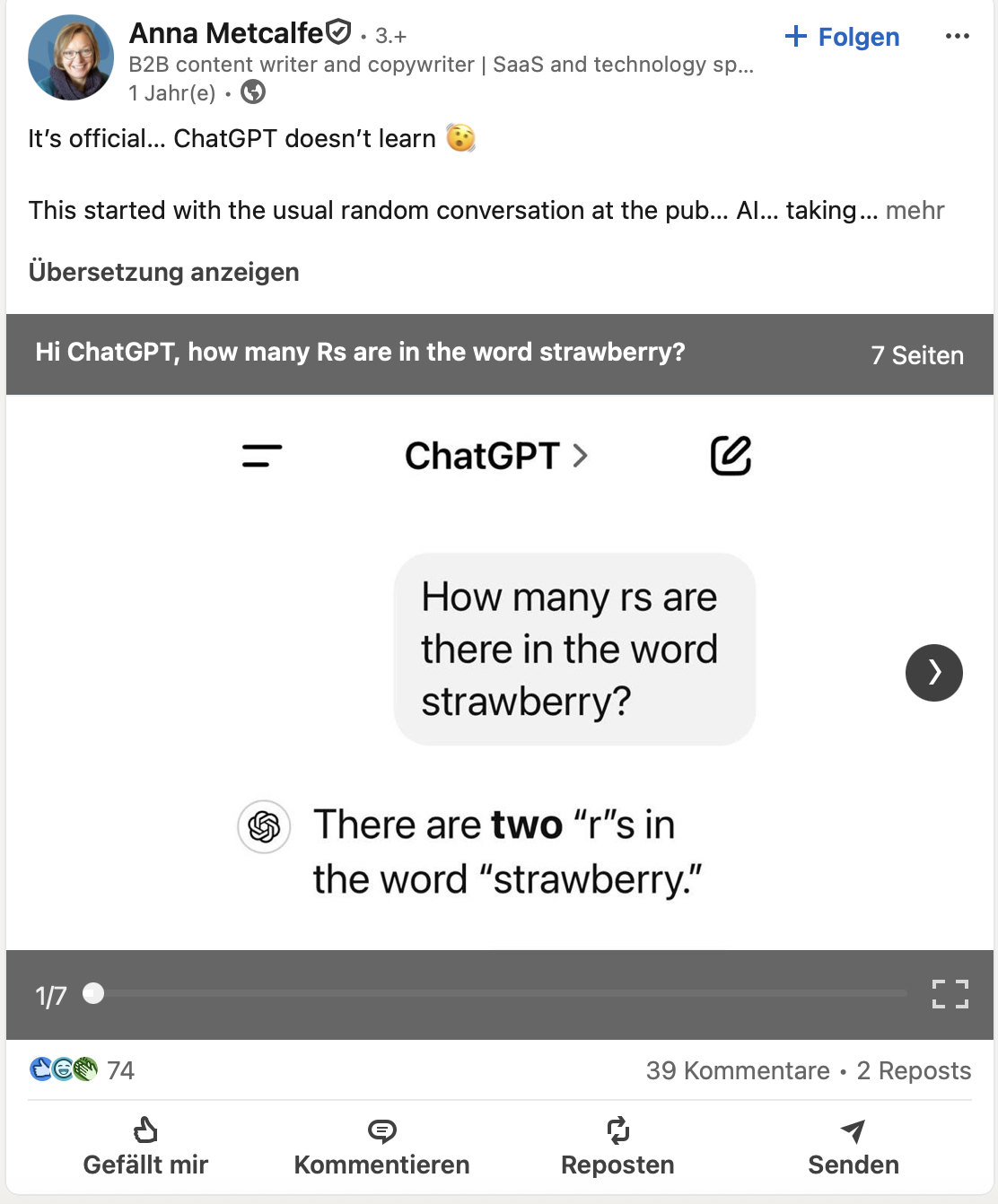
Und plötzlich funktioniert es nicht “ein bisschen” sondern unglaublich gut. Auch genug Paper haben sich mit diesem Problem auseinandergesetzt …
Vor allem Gemini sticht heraus. Das funktioniert eigentlich zu gut. Aber auch Grok und Qwen liefern ZU gute Ergebnisse …
Ist Tokenization gelöst? Tricksen die Modelle im Backend? Oder geht alles mit rechten Dingen zu und die Modelle haben einfach gelernt mit Buchstaben umzugehen? Das schauen wir uns in Teil 3 an … Vielleicht kommen wir aus dem Rabbithole ja zusammen wieder raus :).