“How many r’s are in strawberry?” - die Frage haben wir hundertmal gelesen. Quasi “Running-Gag” und ultimativer Beweis zugleich, dass LLMs im Grunde doch - gaaaanz anders als wir Menschen - ziemlich fehlbar sind.
Und ja, da ist was dran. LLMs haben - ein echtes Problem mit Buchstaben. Das liegt an der Tokenization: Ein LLM sieht nicht “s-t-r-a-w-b-e-r-r-y”. Es sieht Token - Wortfragmente - “str”, “aw” und “berry” vielleicht, oder ganz andere Aufteilungen. Das Konzept “einzelner Buchstabe” existiert in der Wahrnehmung eines LLMs schlicht nicht so, wie wir es kennen. Und die “Strawberry”-Frage ist ein bisschen so, als würdest du einen Farbenblinden fragen, welche Farbe ein Gegenstand hat. Er wird die Frage einfach nicht zuverlässig beantworten können - nicht weil er doof ist, sondern weil ihm einfach die nötige Wahrnehmung dafür fehlt.
Ist das ein Problem? Eigentlich nicht, denn es gibt Workarounds. Code Execution zum Beispiel. Ein LLM kann Python-Code schreiben, der die Buchstaben zählt, und kommt damit easy auf das richtige Ergebnis. Problem gelöst, weiter im Text. Aber darum geht’s ja gar nicht - eher ums Prinzip!
ZWEI WELTEN
Vor zwei Monaten bin ich in eine lange, etwas hitzige Diskussion mit Maria Sukhareva auf LinkedIn geraten. Maria macht super Content zu KI - absolute Folgeempfehlung. Aber ab und an rutscht da ein “Strawberry-Post” dazwischen ;). Wieder als Beispiel, das zeigen soll, welche grundlegenden Schwächen LLMs haben.
Da bin ich anderer Meinung. Ja, LLMs können bestimmte Dinge nicht gut. Aber ein grundsätzliches Problem? Das sehe ich nicht.
Auf LinkedIn macht sich ein Sentiment breit, das ungefähr so klingt: “Die Modelle sind ja ganz nett, aber sie machen SOOO dumme Fehler. So richtig gut werden die nie.” Sie können nicht zählen, sie scheitern an einfachsten Rechenaufgaben. Und das neueste Beispiel, das durch unsere Timelines gespült wird: “Ich will zur Waschstraße und mein Auto waschen. Die ist 100 Meter entfernt. Soll ich fahren oder lieber hinlaufen?” - und dann sagt ChatGPT … na wenns nur 100 Meter sind dann lauf doch lieber.
Ja, ein bisschen lustig ist das schon.
Aber gleichzeitig habe ich mit Anthropics Opus 4.5 angefangen, intensiv mit Claude Code zu arbeiten. Und ich bin seitdem - es gibt kein anderes Wort dafür - baff. Dinge, an denen ich sonst Tage gearbeitet habe, sind in Minuten erledigt. Und das nicht nur bei Spielzeugprojekten oder auf der grünen Wiese, nicht mit Syntaxfehlern und wiederkehrenden Bugs, sondern bei echten großen, bestehenden Projekten. Hand aufs Herz - oft auch besser als ich das “zu Fuß” könnte.
Da sind sie diese zwei Welten. Die eine diskutiert darüber, ob LLMs Buchstaben zählen können. In der anderen sind wir auf dem besten Wege, dass “Softwareentwicklung gelöst” ist.
DAS “KUNSTPROJEKT”
Alter, wir führen echt die falschen Diskussionen.
Mir kam ein kleines “Kunstprojekt” in den Sinn: Was, wenn ich ein LLM benutze, um zu schauen, wie gut LLMs denn tatsächlich Buchstaben zählen können?
Simple Idee und (Spoiler!) überraschendes Ergebnis!
Ich verwende Claude Code - also ein LLM - um “StrawberryBench” zu bauen. Einen vollständigen und nachvollziehbaren Benchmark zum Thema Buchstabenzählen. Nicht ich schreibe den Code und erstelle den Datensatz - das macht Claude Code. Konkret soll es folgendes erledigen:
- Einen Benchmark-Datensatz zum Buchstabenzählen, veröffentlicht als Hugging Face Dataset
- Ein Benchmark-Script auf GitHub, das die aktuellsten + besten Modelle gegen diesen Datensatz laufen lässt.
- Die Ausführung des Benchmarks selbst.
- Eine systematische Analyse der Ergebnisse.
- Eine Webseite dazu: strawberrybench.fyi.
- Und - weil wir ja gründlich sind - ein Paper.
Und Claude Code hat das gemacht. Hat den Datensatz generiert, die Scripts geschrieben, den Benchmark durchgerattert, die Ergebnisse ausgewertet. Hat eine Webseite gebaut und ein Paper strukturiert. Ein LLM, das beweist, dass LLMs doch Buchstaben zählen können?
DAS ERGEBNIS
Und dann sehe ich das Ergebnis. Und das war … nicht das, was ich erwartet hatte.
Ich ging davon aus, dass die besten Modelle halbwegs gut Buchstaben zählen können, aber weit von “perfekt” entfernt sein werden. Und ums genaue Ergebnis gings mir auch gar nicht - eher darum diese Wahrnehmungsschere aus “die Modelle können nix” und “Software-Entwicklung ist gelöst und bald vermutlich noch viel mehr” aufzuzeigen.
Aber seht selbst:
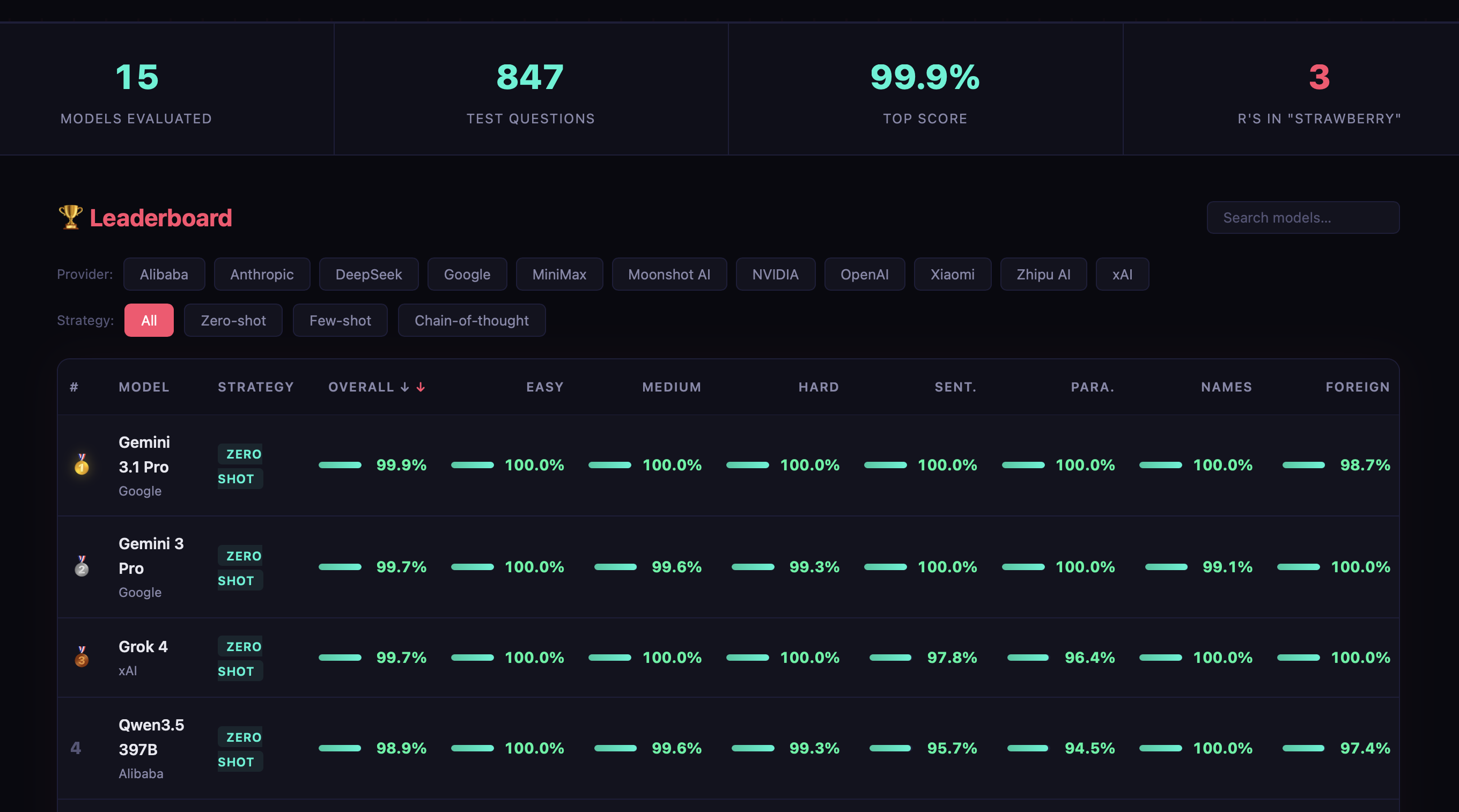
Moment, was? Gemini 3.1 Pro (und 3.0 Pro auch), Grok 4, Qwen3.5 397B, Kimi K2.5, etc … Kurze Wörter, lange Wörter, ganze Sätze und kurze Texte bis ca. 100 Zeichen - quasi PERFEKT?!
Ich war vorsichtig gesagt überrascht. Also dann, Domain registriert, Webseite fertig gemacht, Datensatz bei HuggingFace hochgeladen, GitHub Repo erstellt - LinkedIn Post darf natürlich nicht fehlen. Damit ist die Frage beantwortet, Thema beendet …
… aber halt!
AB INS RABBITHOLE
Das war dann der Punkt, an dem aus einer Übersprungshandlung ein Rabbithole wurde. Drei Tage später nagt plötzlich die Frage: Wie zum Teufel machen die das und wo ist die Grenze?!?
Vier Wochen, unzählige Stunden und ungefähr 120 Euro an OpenRouter-, Hugging Face Endpoints- und Claude Code-Credits und eine Menge Kaffee später bin ich schlauer. Deutlich schlauer. Über Buchstaben, über Benchmarks, über die Art und Weise, wie Reasoning-Modelle denken. Und darüber, warum die Diskussion um “dumme LLMs” an der Realität vorbeigeht.
Aber das ist Stoff für Teil 2 … den gibts in ein paar Tagen.